![]()
Sep-2023 New Version Professional-Machine-Learning-Engineer Certificate & Helpful Exam Dumps is Online
Professional-Machine-Learning-Engineer Free Certification Exam Material with 150 Q&As
NEW QUESTION # 68
You want to rebuild your ML pipeline for structured data on Google Cloud. You are using PySpark to conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have already moved your raw data into Cloud Storage. How should you build the pipeline on Google Cloud while meeting the speed and processing requirements?
- A. Ingest your data into Cloud SQL convert your PySpark commands into SQL queries to transform the data, and then use federated queries from BigQuery for machine learning
- B. Ingest your data into BigQuery using BigQuery Load, convert your PySpark commands into BigQuery SQL queries to transform the data, and then write the transformations to a new table
- C. Convert your PySpark into SparkSQL queries to transform the data and then run your pipeline on Dataproc to write the data into BigQuery.
- D. Use Data Fusion's GUI to build the transformation pipelines, and then write the data into BigQuery
Answer: C
NEW QUESTION # 69
You are an ML engineer at a manufacturing company You are creating a classification model for a predictive maintenance use case You need to predict whether a crucial machine will fail in the next three days so that the repair crew has enough time to fix the machine before it breaks. Regular maintenance of the machine is relatively inexpensive, but a failure would be very costly You have trained several binary classifiers to predict whether the machine will fail. where a prediction of 1 means that the ML model predicts a failure.
You are now evaluating each model on an evaluation dataset. You want to choose a model that prioritizes detection while ensuring that more than 50% of the maintenance jobs triggered by your model address an imminent machine failure. Which model should you choose?
- A. The model with the highest precision where recall is greater than 0.5.
- B. The model with the highest area under the receiver operating characteristic curve (AUC ROC) and precision greater than 0 5
- C. The model with the lowest root mean squared error (RMSE) and recall greater than 0.5.
- D. The model with the highest recall where precision is greater than 0.5.
Answer: D
Explanation:
In predictive maintenance, the goal is to identify which machines are likely to fail soon, so that the repair crew can fix them before they break. In this context, it is important to prioritize detection, while also ensuring that more than 50% of the maintenance jobs triggered by your model address an imminent machine failure.
Recall is a metric that measures the proportion of actual positive observations that are correctly predicted as such by the model. In this case, recall is a good metric to use because it measures how well the model is able to identify the machines that are likely to fail soon.
Precision is a metric that measures the proportion of positive predictions that are actually true. In this case, precision is also important because it measures how many of the machines that the model predicts will fail soon, actually do fail soon.
By combining these two metrics, you can ensure that your model is able to identify the machines that are likely to fail soon with a high degree of accuracy. In this case, the model with the highest recall where precision is greater than 0.5 will be the best model, as it will have a high ability to identify the machines that are likely to fail soon and also it will have a high degree of accuracy.
Reference:
Recall and Precision
Predictive Maintenance
Metrics for classification
NEW QUESTION # 70
A machine learning (ML) specialist wants to secure calls to the Amazon SageMaker Service API. The specialist has configured Amazon VPC with a VPC interface endpoint for the Amazon SageMaker Service API and is attempting to secure traffic from specific sets of instances and IAM users. The VPC is configured with a single public subnet.
Which combination of steps should the ML specialist take to secure the traffic? (Choose two.)
- A. Modify the ACL on the endpoint network interface to restrict access to the instances.
- B. Add a SageMaker Runtime VPC endpoint interface to the VPC.
- C. Modify the users' IAM policy to allow access to Amazon SageMaker Service API calls only.
- D. Add a VPC endpoint policy to allow access to the IAM users.
- E. Modify the security group on the endpoint network interface to restrict access to the instances.
Answer: D,E
Explanation:
Explanation/Reference: https://aws.amazon.com/blogs/machine-learning/private-package-installation-in-amazon- sagemaker-running-in-internet-free-mode/
NEW QUESTION # 71
You are a data scientist at an industrial equipment manufacturing company. You are developing a regression model to estimate the power consumption in the company's manufacturing plants based on sensor data collected from all of the plants. The sensors collect tens of millions of records every day. You need to schedule daily training runs for your model that use all the data collected up to the current date. You want your model to scale smoothly and require minimal development work. What should you do?
- A. Develop a custom scikit-learn regression model, and optimize it using Vertex AI Training.
- B. Develop a regression model using BigQuery ML.
- C. Develop a custom TensorFlow regression model, and optimize it using Vertex AI Training.
- D. Train a regression model using AutoML Tables.
Answer: D
NEW QUESTION # 72
A company ingests machine learning (ML) data from web advertising clicks into an Amazon S3 data lake. Click data is added to an Amazon Kinesis data stream by using the Kinesis Producer Library (KPL). The data is loaded into the S3 data lake from the data stream by using an Amazon Kinesis Data Firehose delivery stream.
As the data volume increases, an ML specialist notices that the rate of data ingested into Amazon S3 is relatively constant. There also is an increasing backlog of data for Kinesis Data Streams and Kinesis Data Firehose to ingest.
Which next step is MOST likely to improve the data ingestion rate into Amazon S3?
- A. Increase the number of shards for the data stream.
- B. Decrease the retention period for the data stream.
- C. Add more consumers using the Kinesis Client Library (KCL).
- D. Increase the number of S3 prefixes for the delivery stream to write to.
Answer: A
Explanation:
Explanation/Reference:
NEW QUESTION # 73
A technology startup is using complex deep neural networks and GPU compute to recommend the company's products to its existing customers based upon each customer's habits and interactions. The solution currently pulls each dataset from an Amazon S3 bucket before loading the data into a TensorFlow model pulled from the company's Git repository that runs locally. This job then runs for several hours while continually outputting its progress to the same S3 bucket. The job can be paused, restarted, and continued at any time in the event of a failure, and is run from a central queue.
Senior managers are concerned about the complexity of the solution's resource management and the costs involved in repeating the process regularly. They ask for the workload to be automated so it runs once a week, starting Monday and completing by the close of business Friday.
Which architecture should be used to scale the solution at the lowest cost?
- A. Implement the solution using AWS Deep Learning Containers and run the container as a job using AWS Batch on a GPU-compatible Spot Instance
- B. Implement the solution using a low-cost GPU-compatible Amazon EC2 instance and use the AWS Instance Scheduler to schedule the task
- C. Implement the solution using Amazon ECS running on Spot Instances and schedule the task using the ECS service scheduler
- D. Implement the solution using AWS Deep Learning Containers, run the workload using AWS Fargate running on Spot Instances, and then schedule the task using the built-in task scheduler
Answer: D
NEW QUESTION # 74
You work for an advertising company and want to understand the effectiveness of your company's latest advertising campaign. You have streamed 500 MB of campaign data into BigQuery. You want to query the table, and then manipulate the results of that query with a pandas dataframe in an Al Platform notebook. What should you do?
- A. Use Al Platform Notebooks' BigQuery cell magic to query the data, and ingest the results as a pandas dataframe
- B. From a bash cell in your Al Platform notebook, use the bq extract command to export the table as a CSV file to Cloud Storage, and then use gsutii cp to copy the data into the notebook Use pandas. read_csv to ingest the file as a pandas dataframe
- C. Download your table from BigQuery as a local CSV file, and upload it to your Al Platform notebook instance Use pandas. read_csv to ingest the file as a pandas dataframe
- D. Export your table as a CSV file from BigQuery to Google Drive, and use the Google Drive API to ingest the file into your notebook instance
Answer: C
NEW QUESTION # 75
A large mobile network operating company is building a machine learning model to predict customers who are likely to unsubscribe from the service. The company plans to offer an incentive for these customers as the cost of churn is far greater than the cost of the incentive.
The model produces the following confusion matrix after evaluating on a test dataset of 100 customers:
Based on the model evaluation results, why is this a viable model for production?
- A. The precision of the model is 86%, which is less than the accuracy of the model.
- B. The model is 86% accurate and the cost incurred by the company as a result of false positives is less than the false negatives.
- C. The model is 86% accurate and the cost incurred by the company as a result of false negatives is less than the false positives.
- D. The precision of the model is 86%, which is greater than the accuracy of the model.
Answer: C
NEW QUESTION # 76
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a machine learning specialist will build a binary classifier based on two features: age of account, denoted by x, and transaction month, denoted by y. The class distributions are illustrated in the provided figure. The positive class is portrayed in red, while the negative class is portrayed in black.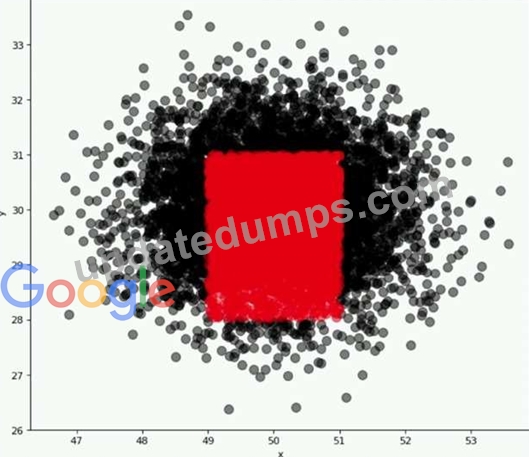
Which model would have the HIGHEST accuracy?
- A. Support vector machine (SVM) with a radial basis function kernel
- B. Single perceptron with a Tanh activation function
- C. Decision tree
- D. Linear support vector machine (SVM)
Answer: A
NEW QUESTION # 77
You built and manage a production system that is responsible for predicting sales numbers. Model accuracy is crucial, because the production model is required to keep up with market changes. Since being deployed to production, the model hasn't changed; however the accuracy of the model has steadily deteriorated. What issue is most likely causing the steady decline in model accuracy?
- A. Too few layers in the model for capturing information
- B. Lack of model retraining
- C. Poor data quality
- D. Incorrect data split ratio during model training, evaluation, validation, and test
Answer: D
NEW QUESTION # 78
A Data Science team within a large company uses Amazon SageMaker notebooks to access data stored in Amazon S3 buckets. The IT Security team is concerned that internet-enabled notebook instances create a security vulnerability where malicious code running on the instances could compromise data privacy. The company mandates that all instances stay within a secured VPC with no internet access, and data communication traffic must stay within the AWS network.
How should the Data Science team configure the notebook instance placement to meet these requirements?
- A. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has S3 VPC endpoints and Amazon SageMaker VPC endpoints attached to it.
- B. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has a NAT gateway and an associated security group allowing only outbound connections to Amazon S3 and Amazon SageMaker.
- C. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Place the Amazon SageMaker endpoint and S3 buckets within the same VPC.
- D. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Use IAM policies to grant access to Amazon S3 and Amazon SageMaker.
Answer: A
NEW QUESTION # 79
One of your models is trained using data provided by a third-party data broker. The data broker does not reliably notify you of formatting changes in the dat a. You want to make your model training pipeline more robust to issues like this. What should you do?
- A. Use TensorFlow Data Validation to detect and flag schema anomalies.
- B. Use custom TensorFlow functions at the start of your model training to detect and flag known formatting errors.
- C. Use TensorFlow Transform to create a preprocessing component that will normalize data to the expected distribution, and replace values that don't match the schema with 0.
- D. Use tf.math to analyze the data, compute summary statistics, and flag statistical anomalies.
Answer: C
NEW QUESTION # 80
Your team trained and tested a DNN regression model with good results. Six months after deployment, the model is performing poorly due to a change in the distribution of the input dat a. How should you address the input differences in production?
- A. Create alerts to monitor for skew, and retrain the model.
- B. Perform feature selection on the model, and retrain the model with fewer features
- C. Perform feature selection on the model, and retrain the model on a monthly basis with fewer features
- D. Retrain the model, and select an L2 regularization parameter with a hyperparameter tuning service
Answer: A
Explanation:
Data drift doesn't necessarily require feature reselection (e.g. by L2 regularization). https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#challenges Data values skews: These skews are significant changes in the statistical properties of data, which means that data patterns are changing, and you need to trigger a retraining of the model to capture these changes. https://developers.google.com/machine-learning/guides/rules-of-ml/#rule_37_measure_trainingserving_skew
NEW QUESTION # 81
A Data Scientist is developing a machine learning model to classify whether a financial transaction is fraudulent. The labeled data available for training consists of 100,000 non-fraudulent observations and 1,000 fraudulent observations.
The Data Scientist applies the XGBoost algorithm to the data, resulting in the following confusion matrix when the trained model is applied to a previously unseen validation dataset. The accuracy of the model is 99.1%, but the Data Scientist has been asked to reduce the number of false negatives.
Which combination of steps should the Data Scientist take to reduce the number of false positive predictions by the model? (Choose two.)
- A. Change the XGBoost eval_metric parameter to optimize based on AUC instead of error.
- B. Change the XGBoost eval_metric parameter to optimize based on rmse instead of error.
- C. Increase the XGBoost max_depth parameter because the model is currently underfitting the data.
- D. Decrease the XGBoost max_depth parameter because the model is currently overfitting the data.
- E. Increase the XGBoost scale_pos_weight parameter to adjust the balance of positive and negative weights.
Answer: A,D
NEW QUESTION # 82
A Machine Learning Specialist must build out a process to query a dataset on Amazon S3 using Amazon Athena. The dataset contains more than 800,000 records stored as plaintext CSV files. Each record contains
200 columns and is approximately 1.5 MB in size. Most queries will span 5 to 10 columns only.
How should the Machine Learning Specialist transform the dataset to minimize query runtime?
- A. Convert the records to JSON format.
- B. Convert the records to GZIP CSV format.
- C. Convert the records to Apache Parquet format.
- D. Convert the records to XML format.
Answer: C
Explanation:
Using compressions will reduce the amount of data scanned by Amazon Athena, and also reduce your S3 bucket storage. It's a Win-Win for your AWS bill. Supported formats: GZIP, LZO, SNAPPY (Parquet) and ZLIB.
Reference: https://www.cloudforecast.io/blog/using-parquet-on-athena-to-save-money-on-aws/
NEW QUESTION # 83
You are an ML engineer at a global car manufacturer. You need to build an ML model to predict car sales in different cities around the world. Which features or feature crosses should you use to train city-specific relationships between car type and number of sales?
- A. Three individual features binned latitude, binned longitude, and one-hot encoded car type
- B. One feature obtained as an element-wise product between binned latitude, binned longitude, and one-hot encoded car type
- C. Two feature crosses as a element-wise product the first between binned latitude and one-hot encoded car type, and the second between binned longitude and one-hot encoded car type
- D. One feature obtained as an element-wise product between latitude, longitude, and car type
Answer: B
NEW QUESTION # 84
You have deployed multiple versions of an image classification model on Al Platform. You want to monitor the performance of the model versions overtime. How should you perform this comparison?
- A. Compare the loss performance for each model on the validation data
- B. Compare the receiver operating characteristic (ROC) curve for each model using the What-lf Tool
- C. Compare the mean average precision across the models using the Continuous Evaluation feature
- D. Compare the loss performance for each model on a held-out dataset.
Answer: C
Explanation:
https://cloud.google.com/ai-platform/prediction/docs/continuous-evaluation/view-metrics
NEW QUESTION # 85
You have written unit tests for a Kubeflow Pipeline that require custom libraries. You want to automate the execution of unit tests with each new push to your development branch in Cloud Source Repositories. What should you do?
- A. Write a script that sequentially performs the push to your development branch and executes the unit tests on Cloud Run
- B. Using Cloud Build, set an automated trigger to execute the unit tests when changes are pushed to your development branch.
- C. Set up a Cloud Logging sink to a Pub/Sub topic that captures interactions with Cloud Source Repositories. Execute the unit tests using a Cloud Function that is triggered when messages are sent to the Pub/Sub topic
- D. Set up a Cloud Logging sink to a Pub/Sub topic that captures interactions with Cloud Source Repositories Configure a Pub/Sub trigger for Cloud Run, and execute the unit tests on Cloud Run.
Answer: B
Explanation:
https://cloud.google.com/architecture/architecture-for-mlops-using-tfx-kubeflow-pipelines-and-cloud-build#cicd_architecture
NEW QUESTION # 86
You work for a large hotel chain and have been asked to assist the marketing team in gathering predictions for a targeted marketing strategy. You need to make predictions about user lifetime value (LTV) over the next 30 days so that marketing can be adjusted accordingly. The customer dataset is in BigQuery, and you are preparing the tabular data for training with AutoML Tables. This data has a time signal that is spread across multiple columns. How should you ensure that AutoML fits the best model to your data?
- A. Submit the data for training without performing any manual transformations Allow AutoML to handle the appropriate transformations Choose an automatic data split across the training, validation, and testing sets
- B. Submit the data for training without performing any manual transformations Use the columns that have a time signal to manually split your data Ensure that the data in your validation set is from 30 days after the data in your training set and that the data in your testing set is from 30 days after your validation set
- C. Manually combine all columns that contain a time signal into an array Allow AutoML to interpret this array appropriately Choose an automatic data split across the training, validation, and testing sets
- D. Submit the data for training without performing any manual transformations, and indicate an appropriate column as the Time column Allow AutoML to split your data based on the time signal provided, and reserve the more recent data for the validation and testing sets
Answer: B
Explanation:
https://cloud.google.com/automl-tables/docs/data-best-practices#time
NEW QUESTION # 87
A Data Scientist is developing a machine learning model to predict future patient outcomes based on information collected about each patient and their treatment plans. The model should output a continuous value as its prediction. The data available includes labeled outcomes for a set of 4,000 patients. The study was conducted on a group of individuals over the age of 65 who have a particular disease that is known to worsen with age.
Initial models have performed poorly. While reviewing the underlying data, the Data Scientist notices that, out of 4,000 patient observations, there are 450 where the patient age has been input as 0. The other features for these observations appear normal compared to the rest of the sample population How should the Data Scientist correct this issue?
- A. Drop all records from the dataset where age has been set to 0.
- B. Replace the age field value for records with a value of 0 with the mean or median value from the dataset
- C. Drop the age feature from the dataset and train the model using the rest of the features.
- D. Use k-means clustering to handle missing features
Answer: A
Explanation:
Explanation
NEW QUESTION # 88
You are a data scientist at an industrial equipment manufacturing company. You are developing a regression model to estimate the power consumption in the company's manufacturing plants based on sensor data collected from all of the plants. The sensors collect tens of millions of records every day. You need to schedule daily training runs for your model that use all the data collected up to the current date. You want your model to scale smoothly and require minimal development work. What should you do?
- A. Develop a custom PyTorch regression model, and optimize it using Vertex Al Training
- B. Develop a regression model using BigQuery ML.
- C. Develop a custom TensorFlow regression model, and optimize it using Vertex Al Training.
- D. Develop a custom scikit-learn regression model, and optimize it using Vertex Al Training
Answer: B
Explanation:
BigQuery ML is a powerful tool that allows you to build and deploy machine learning models directly within BigQuery, Google's fully-managed, serverless data warehouse. It allows you to create regression models using SQL, which is a familiar and easy-to-use language for many data scientists. It also allows you to scale smoothly and require minimal development work since you don't have to worry about cluster management and it's fully-managed by Google.
BigQuery ML also allows you to run your training on the same data where it's stored, this will minimize data movement, and thus minimize cost and time.
Reference:
BigQuery ML
BigQuery ML for regression
BigQuery ML for scalability
NEW QUESTION # 89
You have written unit tests for a Kubeflow Pipeline that require custom libraries. You want to automate the execution of unit tests with each new push to your development branch in Cloud Source Repositories. What should you do?
- A. Write a script that sequentially performs the push to your development branch and executes the unit tests on Cloud Run
- B. Using Cloud Build, set an automated trigger to execute the unit tests when changes are pushed to your development branch.
- C. Set up a Cloud Logging sink to a Pub/Sub topic that captures interactions with Cloud Source Repositories. Execute the unit tests using a Cloud Function that is triggered when messages are sent to the Pub/Sub topic
- D. Set up a Cloud Logging sink to a Pub/Sub topic that captures interactions with Cloud Source Repositories Configure a Pub/Sub trigger for Cloud Run, and execute the unit tests on Cloud Run.
Answer: B
NEW QUESTION # 90
You work for a company that manages a ticketing platform for a large chain of cinemas. Customers use a mobile app to search for movies they're interested in and purchase tickets in the app. Ticket purchase requests are sent to Pub/Sub and are processed with a Dataflow streaming pipeline configured to conduct the following steps:
1. Check for availability of the movie tickets at the selected cinema.
2. Assign the ticket price and accept payment.
3. Reserve the tickets at the selected cinema.
4. Send successful purchases to your database.
Each step in this process has low latency requirements (less than 50 milliseconds). You have developed a logistic regression model with BigQuery ML that predicts whether offering a promo code for free popcorn increases the chance of a ticket purchase, and this prediction should be added to the ticket purchase process. You want to identify the simplest way to deploy this model to production while adding minimal latency. What should you do?
- A. Run batch inference with BigQuery ML every five minutes on each new set of tickets issued.
- B. Export your model in TensorFlow format, deploy it on Vertex AI, and query the prediction endpoint from your streaming pipeline.
- C. Export your model in TensorFlow format, and add a tfx_bsl.public.beam.RunInference step to the Dataflow pipeline.
- D. Convert your model with TensorFlow Lite (TFLite), and add it to the mobile app so that the promo code and the incoming request arrive together in Pub/Sub.
Answer: A
NEW QUESTION # 91
......
Get The Important Preparation Guide With Professional-Machine-Learning-Engineer Dumps: https://pass4sure.updatedumps.com/Google/Professional-Machine-Learning-Engineer-updated-exam-dumps.html